21.2 Ajuste: función lm
Para el ajuste (estimación de los parámetros) de un modelo lineal a un conjunto de datos (por mínimos cuadrados) se emplea la función lm:
ajuste <- lm(formula, datos, seleccion, pesos, na.action)formulafórmula que especifica el modelo.datosdata.frame opcional con las variables de la formula.seleccionespecificación opcional de un subconjunto de observaciones.pesosvector opcional de pesos (WLS).na.actionopción para manejar los datos faltantes (na.omit).
modelo <- lm(fidelida ~ servconj, datos)
modelo##
## Call:
## lm(formula = fidelida ~ servconj, data = datos)
##
## Coefficients:
## (Intercept) servconj
## 21.98 8.30Al imprimir el ajuste resultante se muestra un pequeño resumen del ajuste (aunque el objeto que contiene los resultados es una lista).
Para obtener un resumen más completo se puede utilizar la función summary().
summary(modelo)##
## Call:
## lm(formula = fidelida ~ servconj, data = datos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -14.1956 -4.0655 0.2944 4.5945 11.9744
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 21.9754 2.6086 8.424 3.34e-13 ***
## servconj 8.3000 0.8645 9.601 9.76e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.432 on 97 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.4872, Adjusted R-squared: 0.482
## F-statistic: 92.17 on 1 and 97 DF, p-value: 9.765e-16plot(fidelida ~ servconj, datos)
abline(modelo)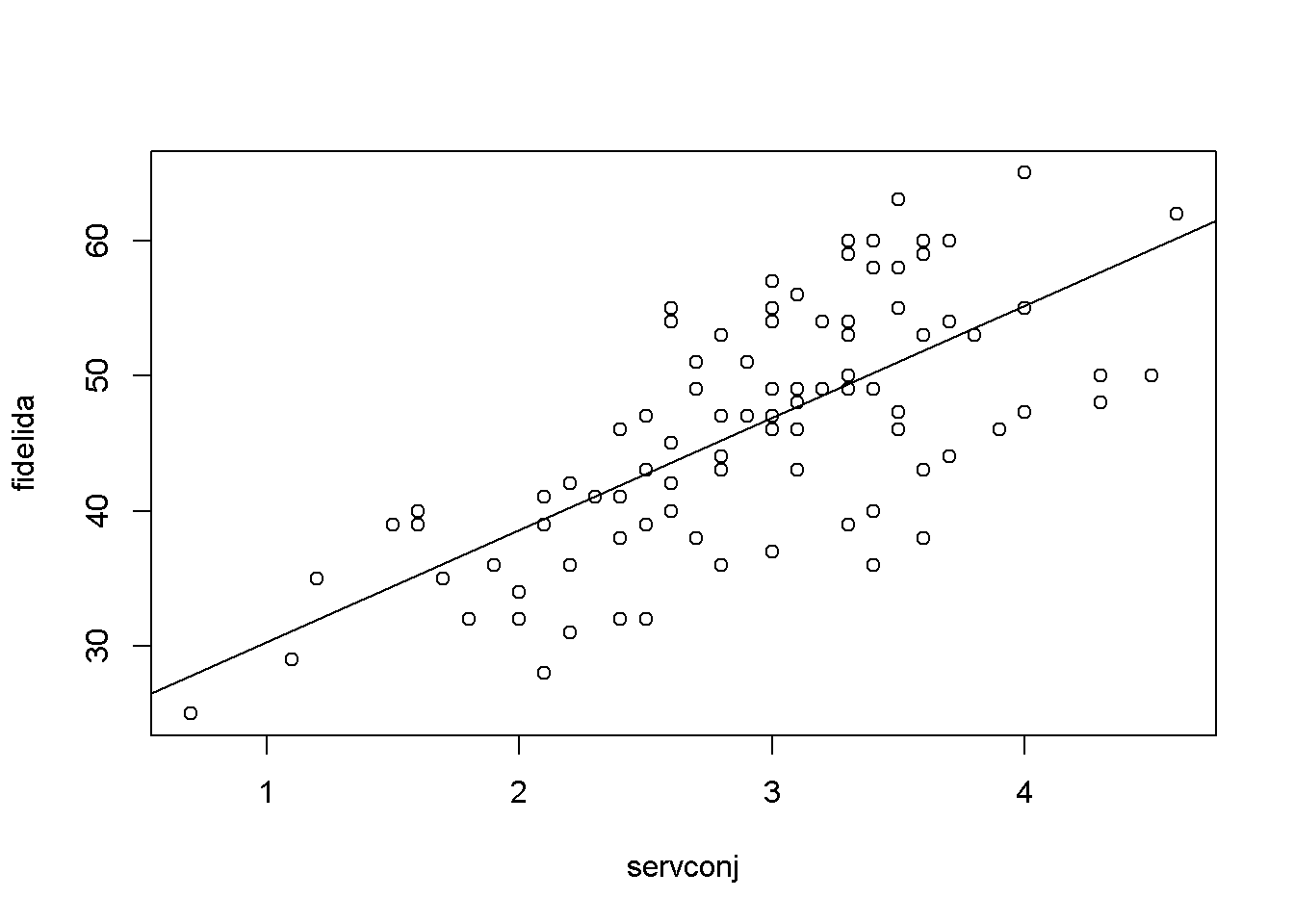
21.2.1 Extracción de información
Para la extracción de información se pueden acceder a los componentes del modelo ajustado o emplear funciones (genéricas). Algunas de las más utilizadas son las siguientes:
| Función | Descripción |
|---|---|
fitted |
valores ajustados |
coef |
coeficientes estimados (y errores estándar) |
confint |
intervalos de confianza para los coeficientes |
residuals |
residuos |
plot |
gráficos de diagnóstico |
termplot |
gráfico de efectos parciales |
anova |
calcula tablas de análisis de varianza (también permite comparar modelos) |
predict |
calcula predicciones para nuevos datos |
Ejemplo:
modelo2 <- lm(fidelida ~ servconj + flexprec, data = hatco)
summary(modelo2)##
## Call:
## lm(formula = fidelida ~ servconj + flexprec, data = hatco)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.2549 -2.2850 0.3411 3.3260 7.0853
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.4617 2.9734 -1.164 0.247
## servconj 7.8287 0.5897 13.276 <2e-16 ***
## flexprec 3.4017 0.3191 10.661 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.375 on 96 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.7652, Adjusted R-squared: 0.7603
## F-statistic: 156.4 on 2 and 96 DF, p-value: < 2.2e-16confint(modelo2)## 2.5 % 97.5 %
## (Intercept) -9.363813 2.440344
## servconj 6.658219 8.999274
## flexprec 2.768333 4.035030anova(modelo2)## Analysis of Variance Table
##
## Response: fidelida
## Df Sum Sq Mean Sq F value Pr(>F)
## servconj 1 3813.6 3813.6 199.23 < 2.2e-16 ***
## flexprec 1 2175.6 2175.6 113.66 < 2.2e-16 ***
## Residuals 96 1837.6 19.1
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# anova(modelo2, modelo)
# termplot(modelo2, partial.resid = TRUE)Muchas de estas funciones genéricas son válidas para otros tipos de modelos (glm, …).
Algunas funciones como summary() devuelven información adicional:
res <- summary(modelo2)
names(res)## [1] "call" "terms" "residuals" "coefficients"
## [5] "aliased" "sigma" "df" "r.squared"
## [9] "adj.r.squared" "fstatistic" "cov.unscaled" "na.action"res$sigma## [1] 4.375074res$adj.r.squared## [1] 0.7603292